生成式 AI 是什么?

摘要:本节课从概念层面对几个关键的技术名词定义和关系进行了清晰的界定。包括人工智能与生成式人工智能、机器学习与深度学习、模型与参数、训练与推理。并一针见血地指出大(语言)模型的本质就是在做「文字接龙」的游戏。
正文
好,我们开始上课。第一堂课要告诉大家的是:什么是生成式人工智能。在讲解生成式人工智能之前,或许我们需要先了解什么是人工智能(Artificial Intelligence,AI)。

从名字来看,人工智能似乎是人类创造出来的、机器所展现的智慧,并非人类本身的智慧。然而,智慧究竟是什么呢?当我们说人工智能是让机器展现智慧时,这只是从字面进行解释。实际上,每个人心中对智慧的理解都不尽相同。
我经常接到邀请去做与AI相关议题的演讲,最近通常会讲ChatGPT。大家普遍认为ChatGPT属于一种人工智能,但也有人持有不同观点。有人觉得会跑来跑去的机器人或者能挑选土豆的电脑才算是人工智能,认为ChatGPT不算。
由此可见,人工智能并没有一个标准的定义,每个人心中对它的想象都不一样。
正因如此,在人工智能相关的论文里,几乎很少提及“人工智能”这个词,因为它是一个定义模糊的词汇。不过,无论我们如何定义智慧这个词,人工智能都可以被看作是一个目标,一个我们想要达成的目标,它不是某一项单一的技术。
那么,什么是生成式人工智能呢?它通常被翻译成Generating AI,其定义相对明确。
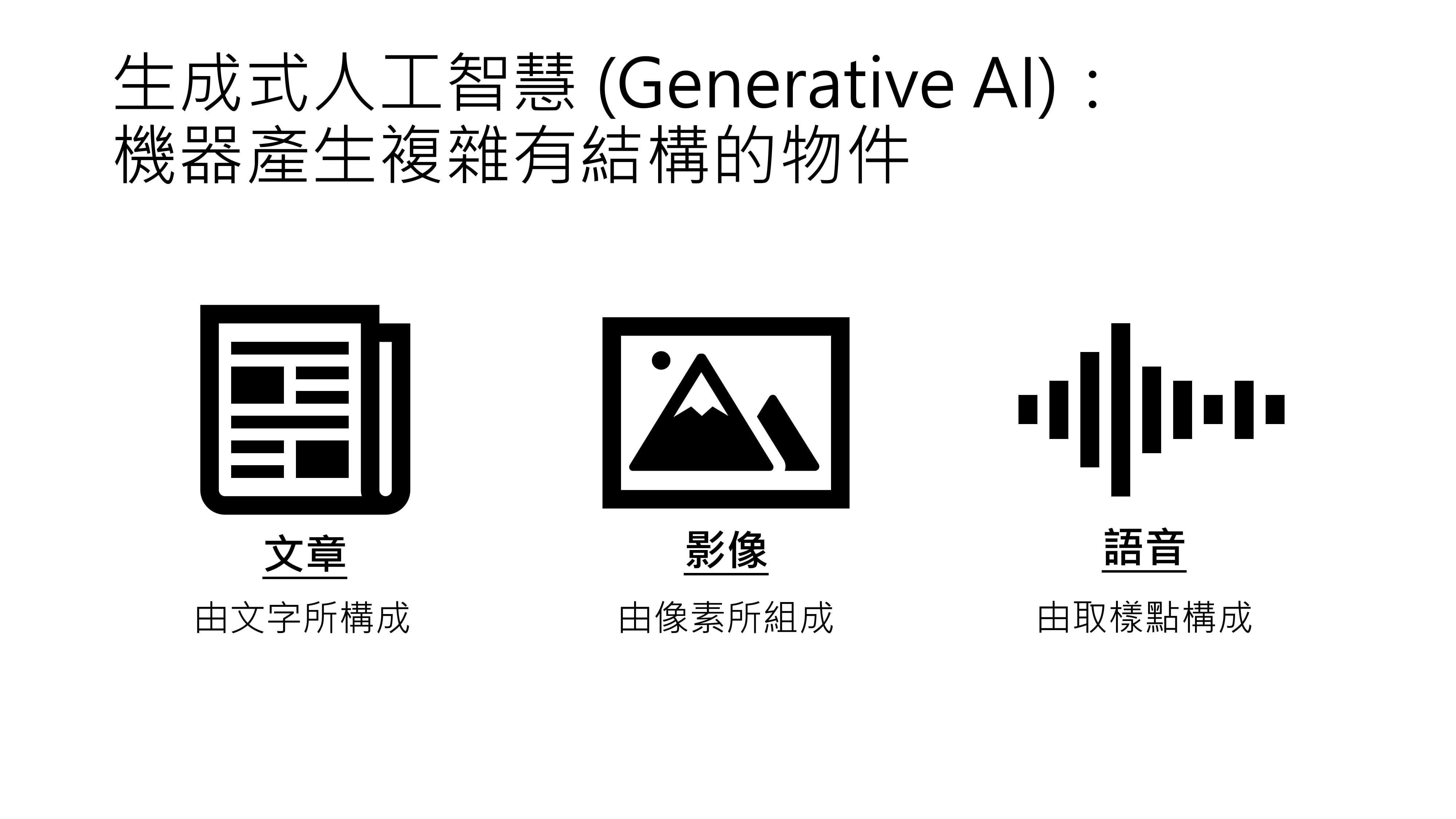
生成式人工智能是让机器产生复杂而有结构的物件,比如文章,文章由一连串文字构成;影像,由一堆像素组成;语音,由一堆取样点组成。如果不了解取样点也没关系,后续讲解语音的生成式AI时会详细说明。

所谓“复杂而有结构”,是指复杂程度要达到无法穷举的地步。
以在ChatGPT上让它写一篇100字、标题为《缝隙的联想》的中文文章为例。
当人工智能写这样一篇文章时,背后要解决一个极为困难的问题。写一篇100字的文章,可能性有多少呢?假设中文常用字为1000个(实际常用字远超这个数量,此处为方便计算假设),那么100字文章的可能性就是1000的100次方,即10的300次方。
这是一个大到难以想象的数字,相比之下,宇宙中原子的数目估计只有10的80次方。机器要从这近乎无穷的可能性中挑出一个合理答案作为回复,显然是非常困难的。当机器解决这个生成式AI的问题时,需要从近乎无穷的可能中找出一个恰当的组合。

为了更好地理解生成式人工智能,我们可以反过来看,什么样的问题不属于生成式AI的问题。比如分类(classification)就不是,分类问题是让机器从有限的选项中做选择。
像Gmail的垃圾邮件侦测功能,收到一封信时,它只有“是垃圾邮件”和“不是垃圾邮件”这两个选项;影像辨识系统在判断一张图片里是猫还是狗时,也只有两个答案。
这种从有限选项中做选择的问题属于分类问题,不属于生成式人工智能。
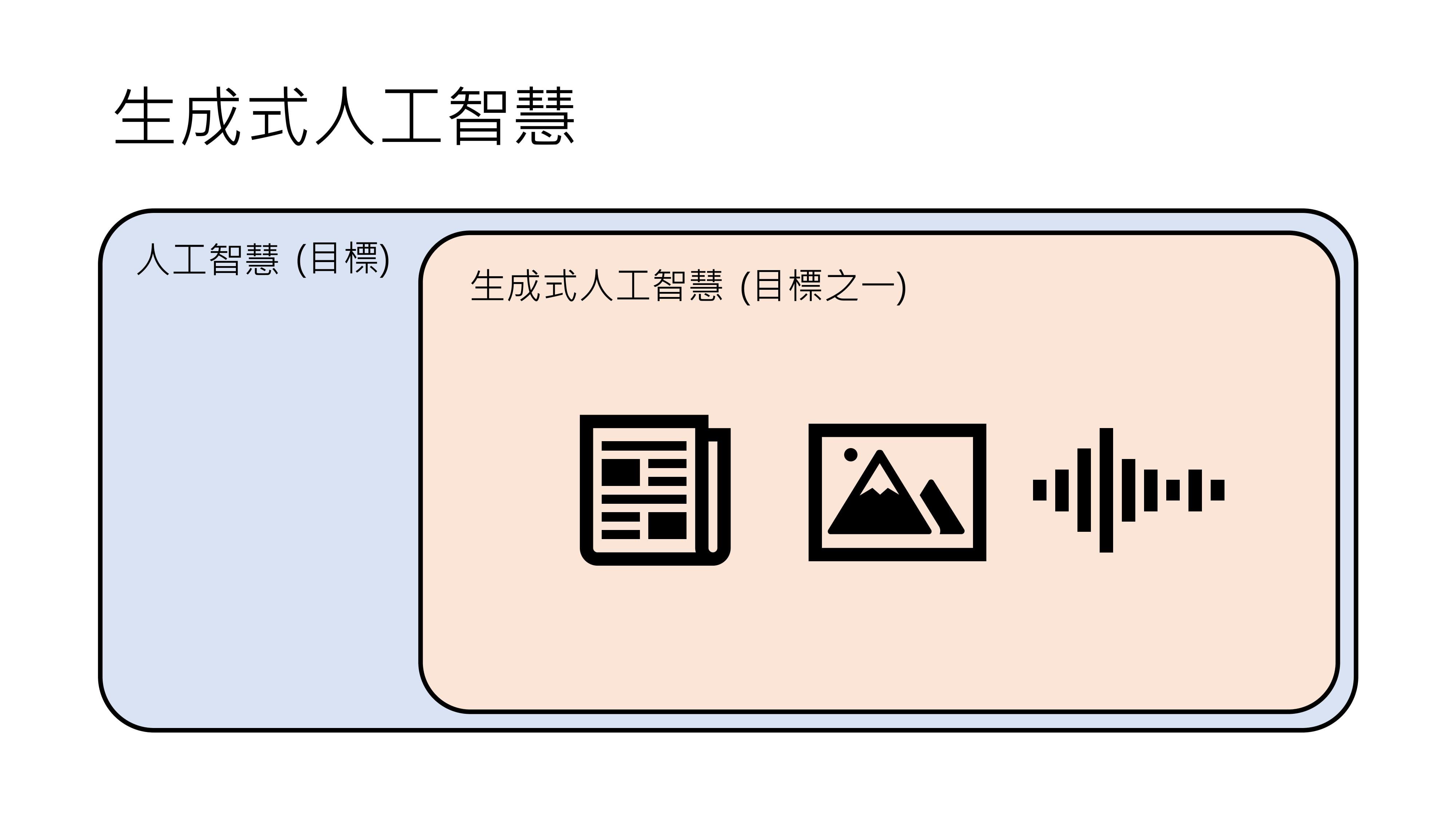
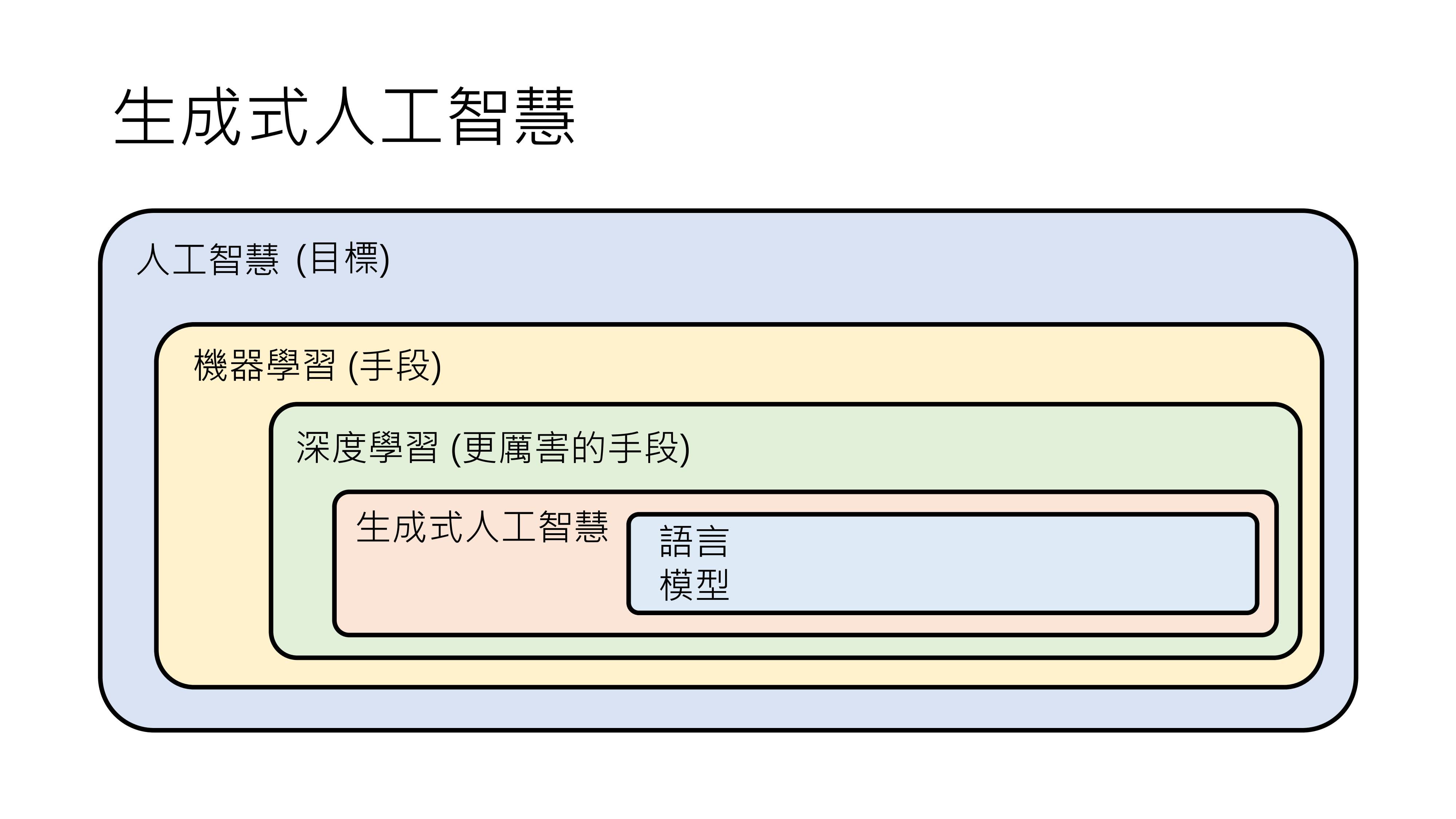
由此可知,生成式人工智能是人工智能的一种,人工智能是一个较为抽象、每个人想象都不太一样的目标,而生成式人工智能是其中一个具体的目标,即让机器产生复杂有结构的物件,如文字、图片、声音等。
在深入探讨生成式人工智能之前,我们来介绍另一个与人工智能经常一起被提及的概念——机器学习(Machine Learning)。
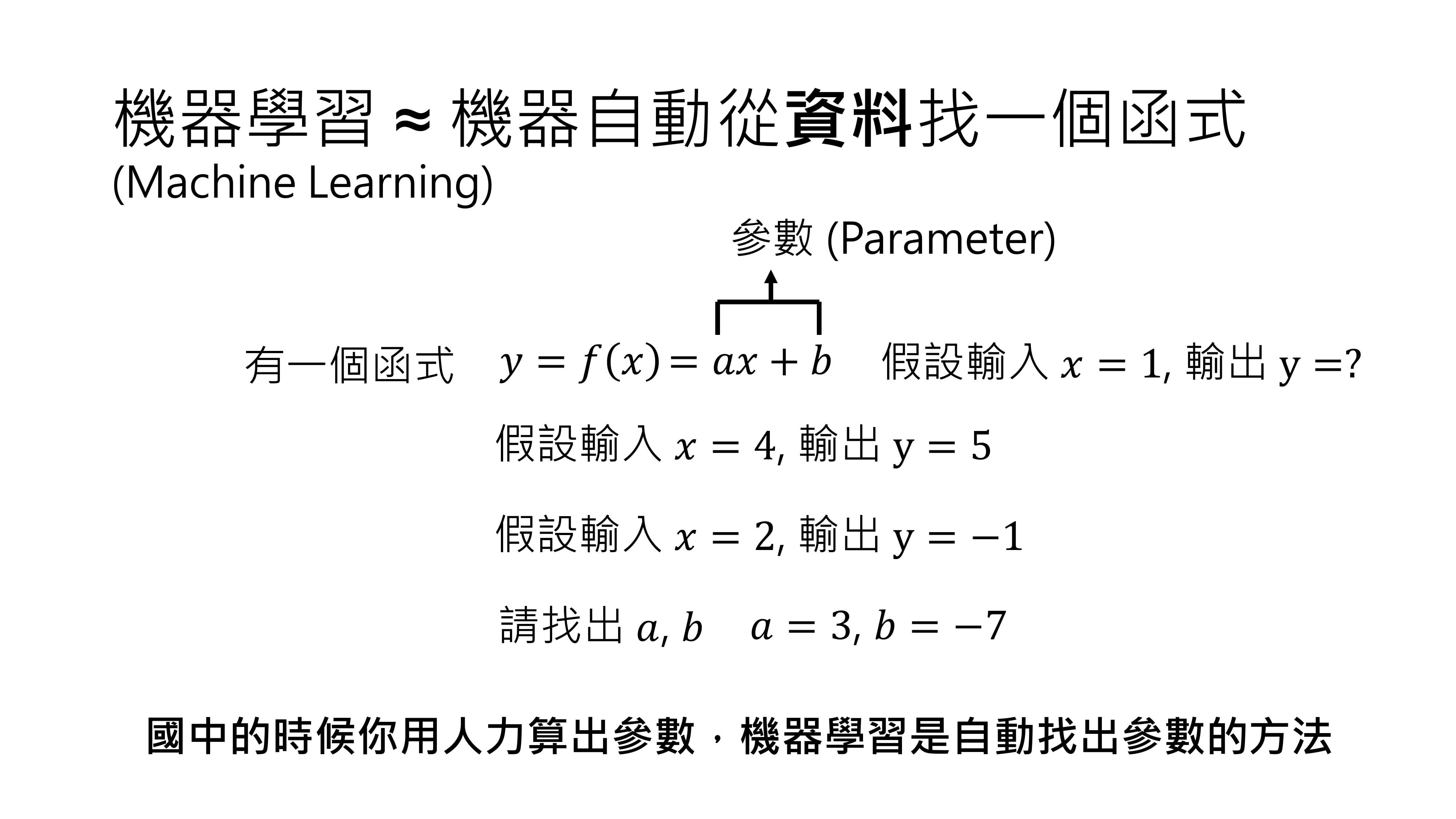
机器学习的定义很明确,就是让机器自动从资料里找出一个函数。
举个具体例子,在初中数学里,我们学过这样的问题:给定一个函数,输出为y,输入为x,函数表示为f(x)=ax + b。
已知当x=4时,y=5;当x=2时,y=-1,求a和b的值。经过运算可以得出a=3,b=-7 。
在机器学习领域,a和b这样的未知数被称为参数(parameter)。有了这两个参数后,代入新的x值就能算出y。机器学习与解这类初中数学问题的不同之处在于,初中时我们靠人力计算参数,而机器学习是通过一系列方法自动算出参数。这是因为实际面临的问题往往比f(x)=ax + b复杂得多。
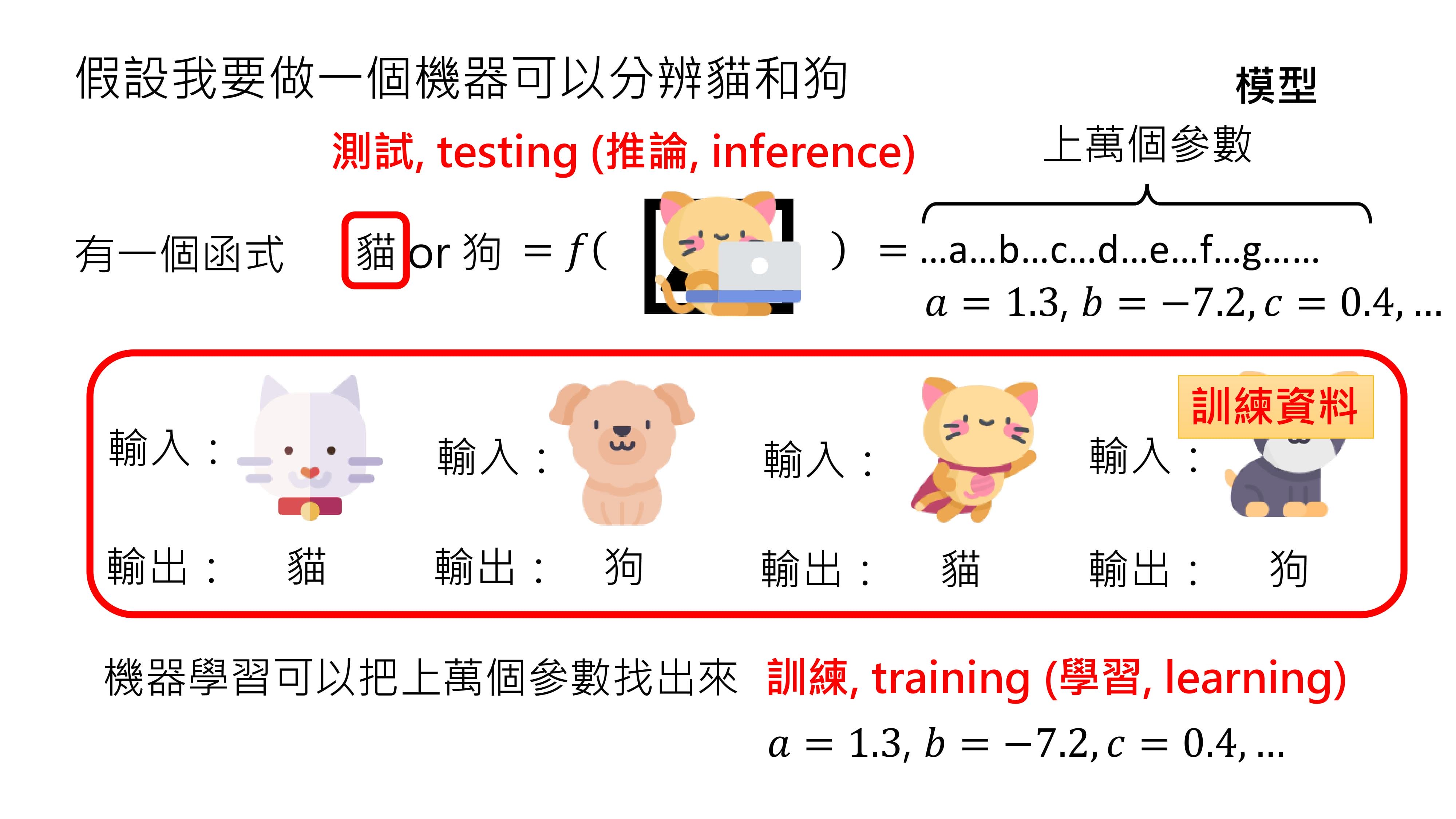
假设让机器学会分辨一张图片里是猫还是狗,就需要一个函数f(图片),其输入是一张图片,输出只有“猫”和“狗”两种可能。
这样的函数非常复杂,绝不是简单的ax + b就能实现,它可能包含上万个参数,这里用abcd等符号表示,但实际上符号远远不够。
这种带有大量未知参数的函数又被称为模型。在不同文献中,“模型”这个词汇的含义可能不同,在本课程中,当提到模型时,指的就是这种带有大量未知参数的函数。
给出题目条件,如输入白色的猫,输出应该是“猫”;输入棕色的狗,输出是“狗”等。机器学习技术就能在这些输入输出条件的限制下,帮助找出这上万个参数。
找出这些参数的过程又叫做训练(training)或学习(learning)。这些帮助找出参数的输入输出条件限制就是训练资料。找出参数后,将其代入模型,就知道函数的具体形式。这时,输入一张新的图片,比如正在打电脑的猫,看看机器会给出什么输出,这个过程叫做测试(Testing)或推论(Inference)。
在机器学习领域,通常用类神经网络(Neuronetwork)来表示这种带有上万个参数的函数。有人认为类神经网络和人类大脑有关,是模仿人类大脑学习的,其实这是一种误解。
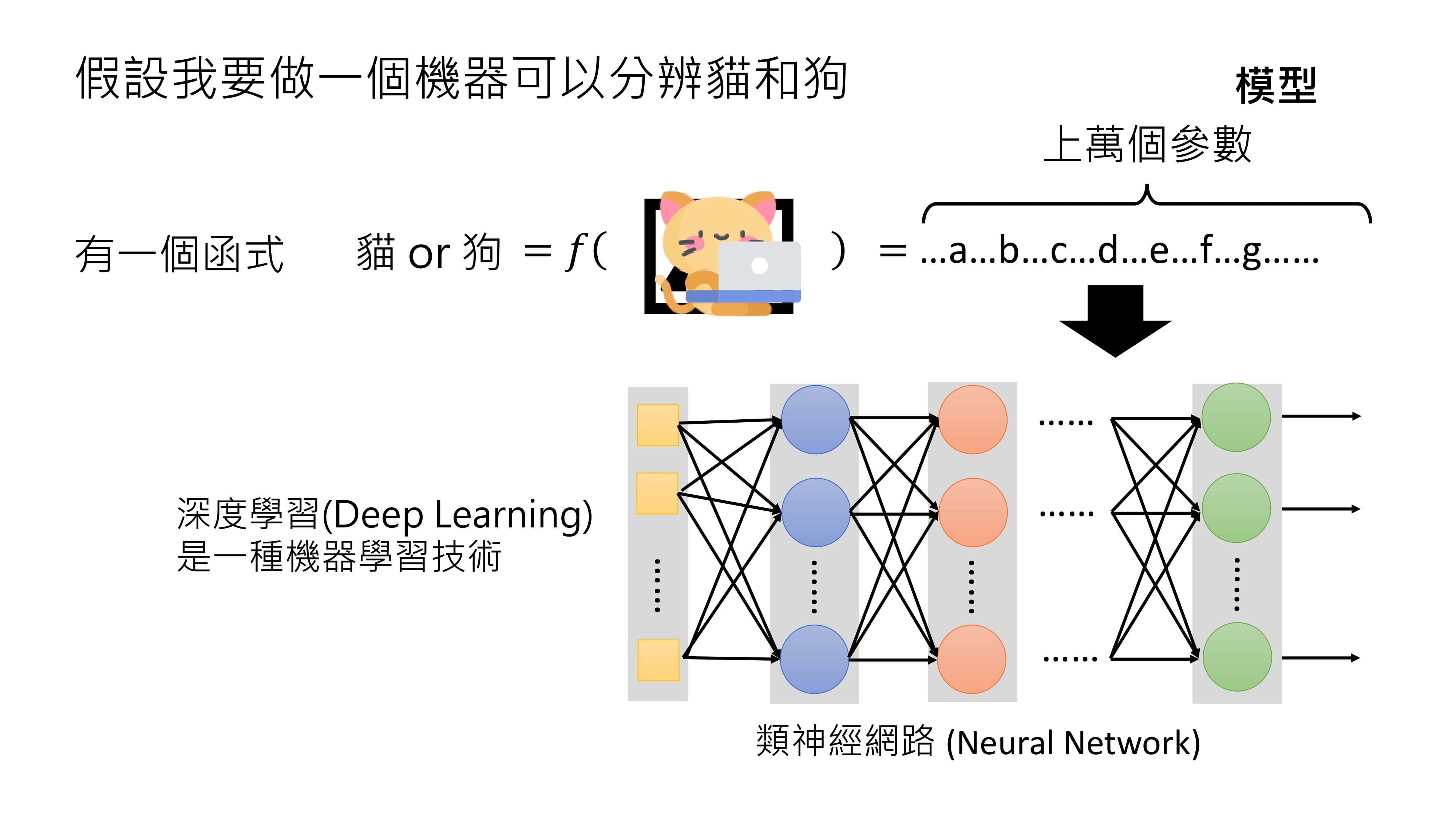
类神经网络本质上就是一个有大量参数的函数,当用类神经网络来描述这个函数,并解出这些参数时,所运用的技术就是深度学习(deep learning)。所以,深度学习是机器学习的一种。当然,描述函数还有其他方法,但使用类神经网络来描述就是在进行深度学习。
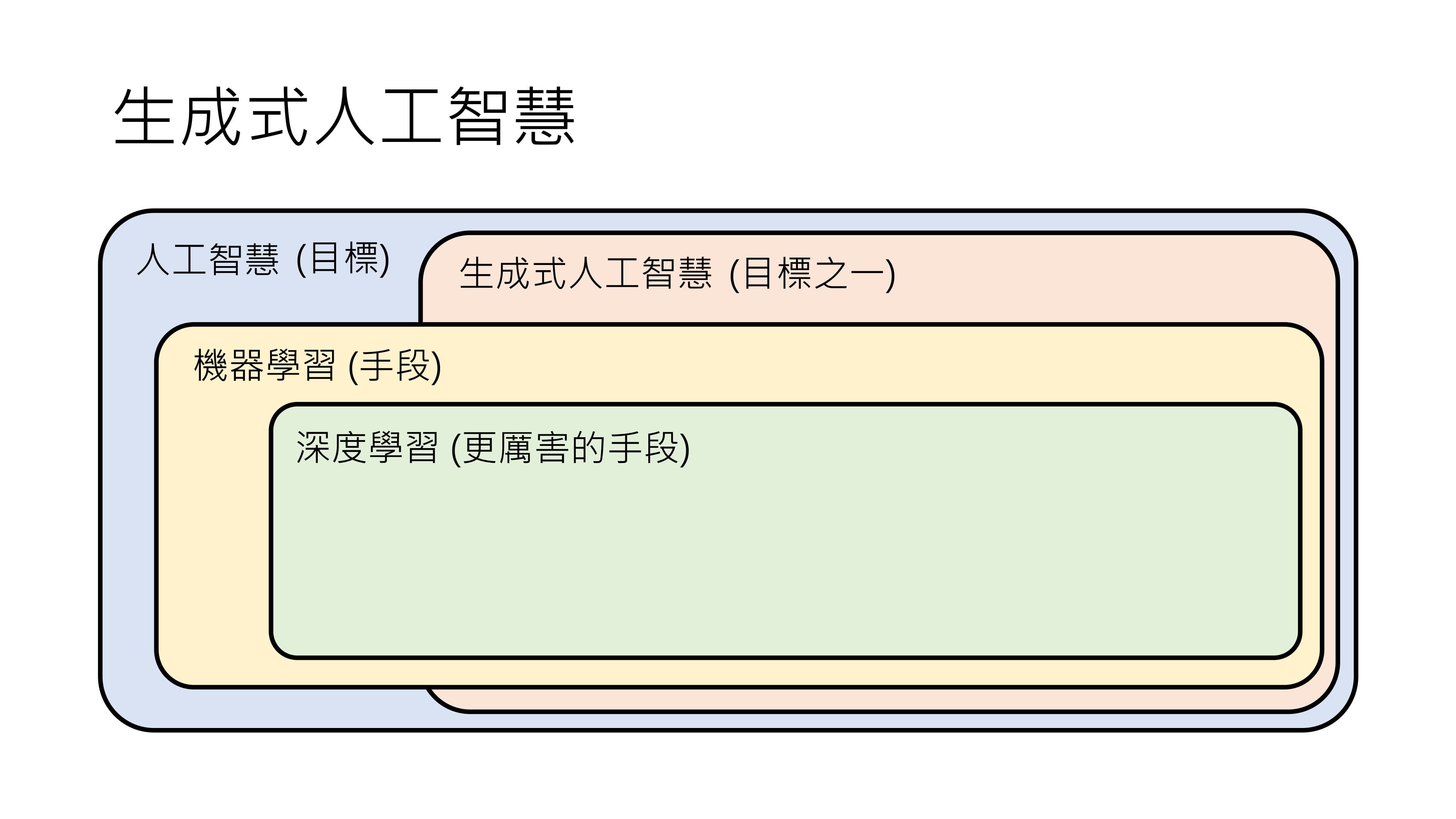
机器学习是一种手段,它与生成式人工智能有交集,也有各自独立的部分。
生成式人工智能既可以用机器学习来解决,也可以用非机器学习的方法解决;机器学习也并非只能解决生成式人工智能的问题,还能解决分类等其他问题。深度学习是机器学习的一种。
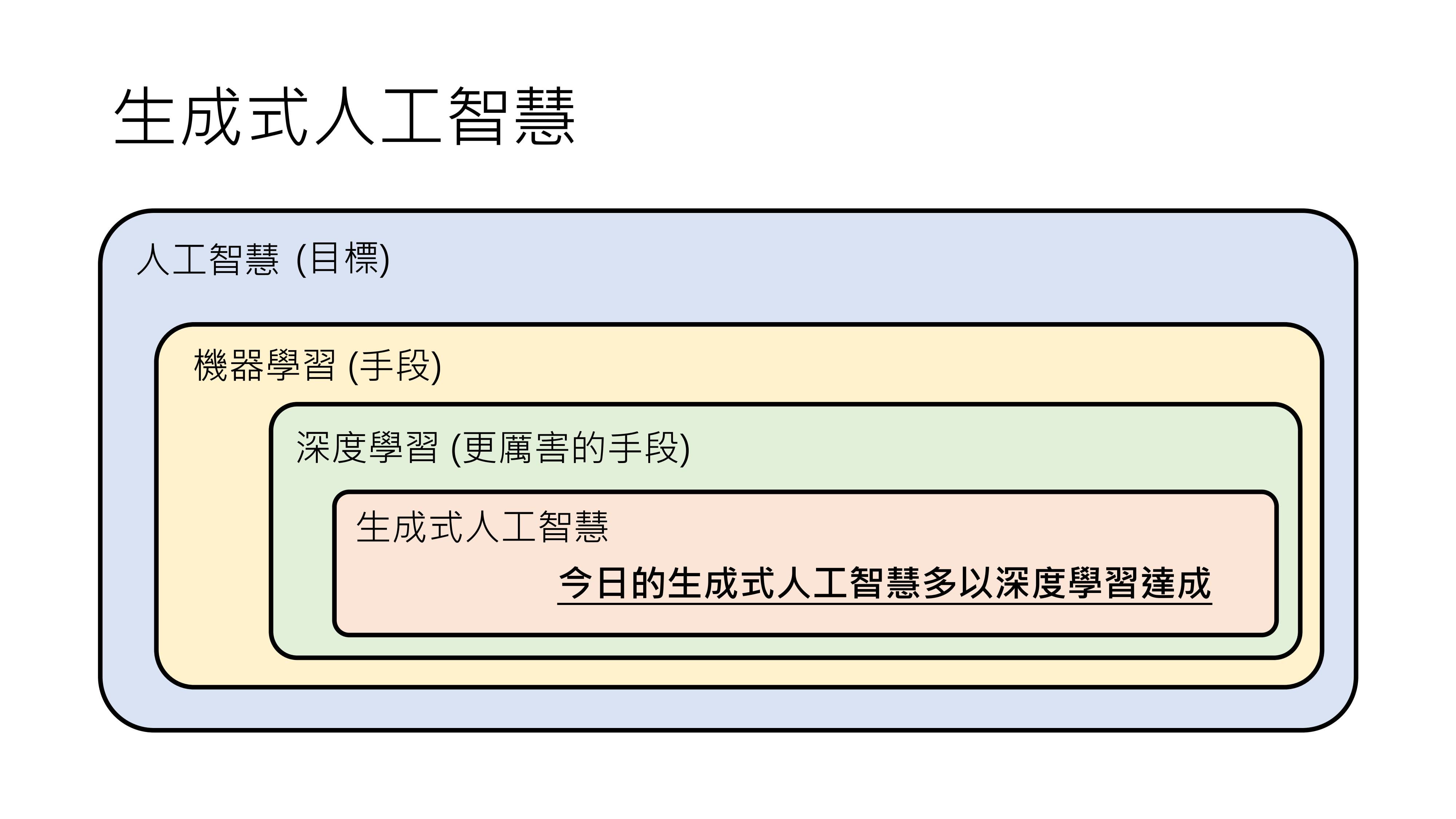
在网络文章中,关于生成式人工智能、深度学习、机器学习的关系,常见的一种表示是把生成式人工智能放在机器学习里面,这种说法也能接受。因为生成式人工智能是一个非常困难的问题,或许其他手段难以达到令人满意的结果,所以通常会用深度学习技术来实现。
也有人把生成式人工智能放在深度学习里面,虽然深度学习是一种技术,生成式人工智能是一个目标,但由于实际中常用深度学习技术来实现生成式人工智能,所以这种说法也可以理解。
那么,机器学习和深度学习如何解决生成式人工智能的问题呢?
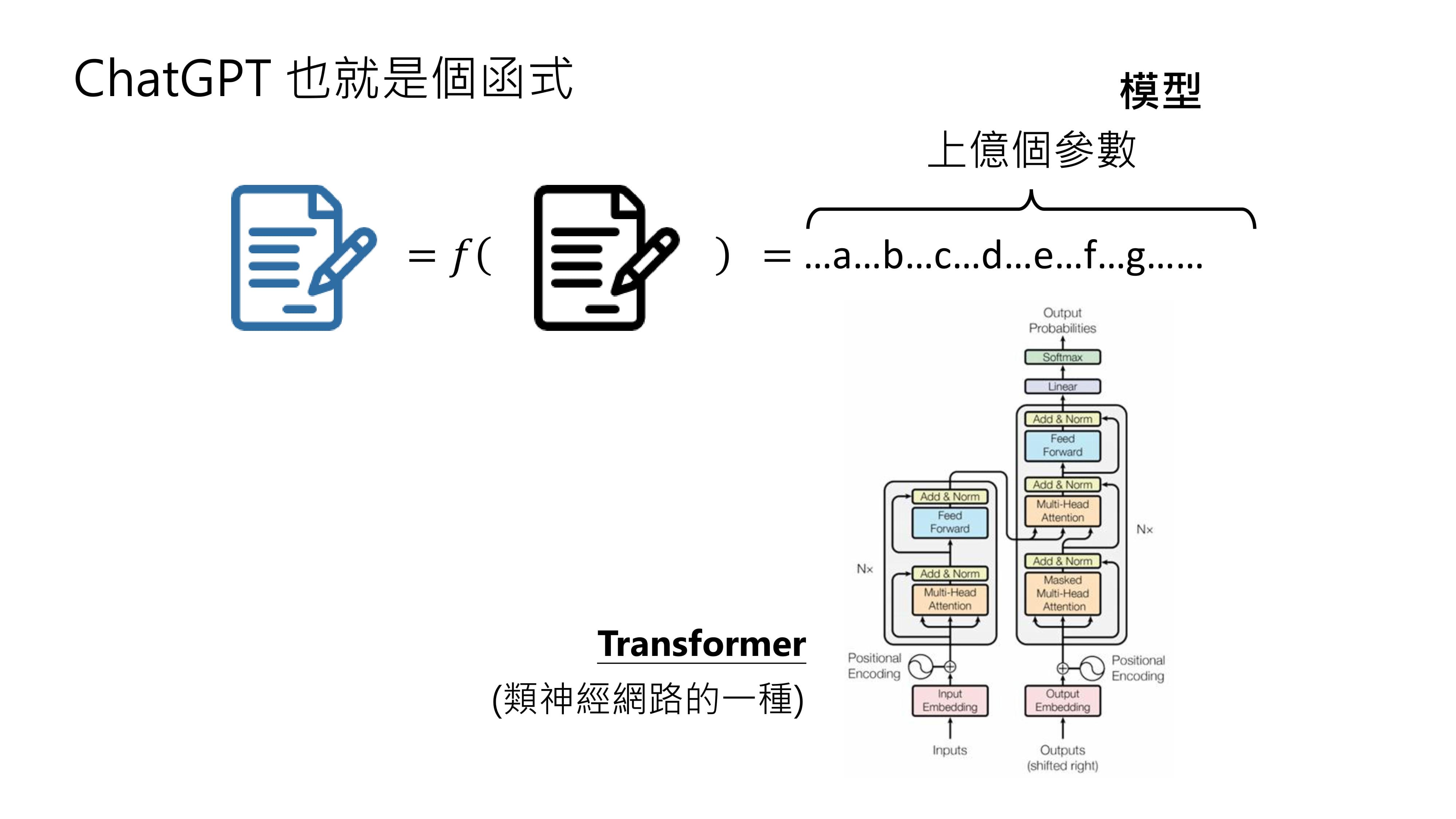
以ChatGPT为例,它也可以被看作是一个函数,输入是一段文字,输出是给用户的回复。
ChatGPT功能强大,能对各种问题做出回应,其背后的函数非常复杂,可能包含上亿个或数十亿个参数。这个带有大量参数的模型是类神经网络的一种,叫做Transformer。
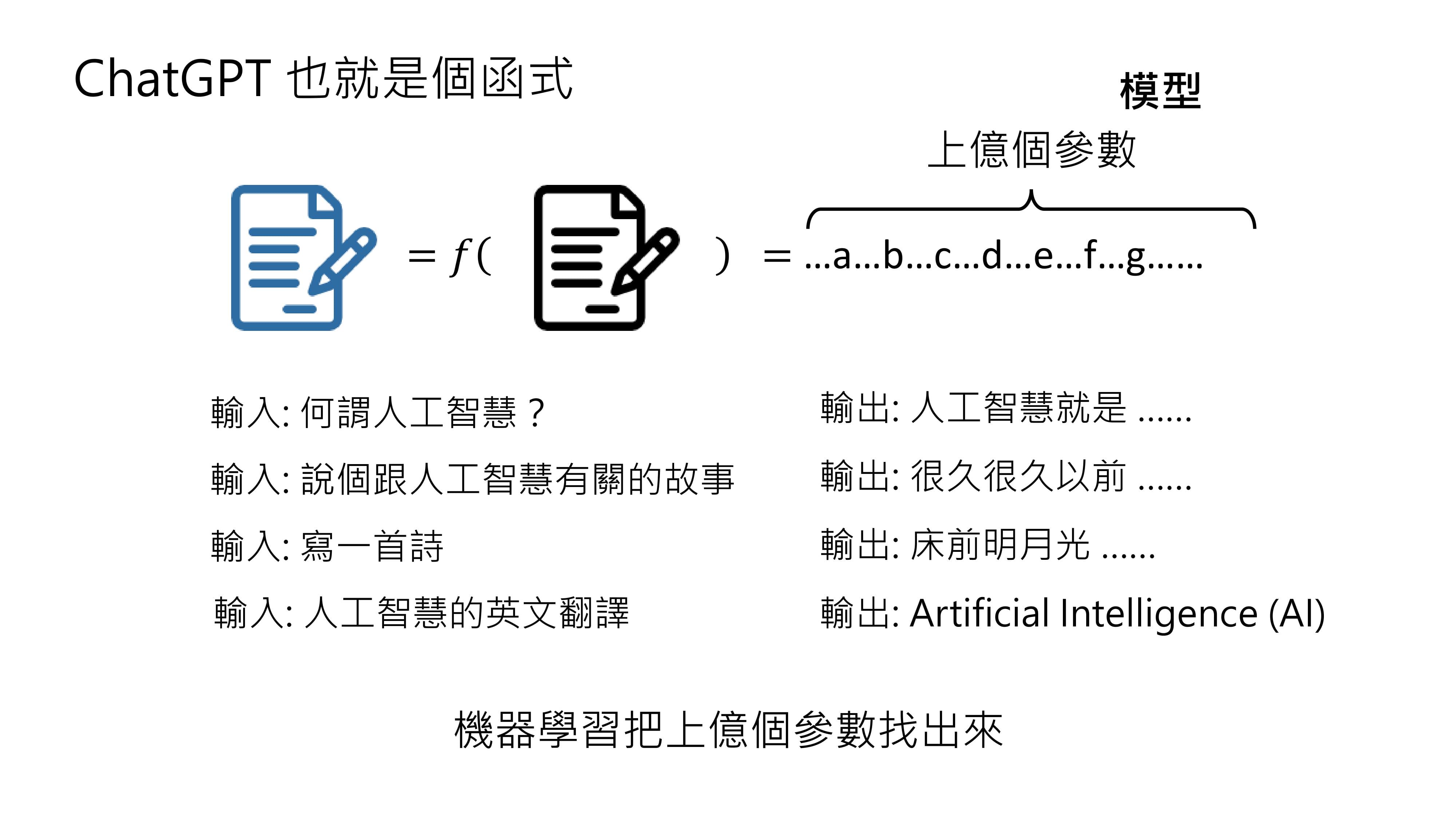
从机器学习的概念来讲,打造ChatGPT这样的人工智能,需要准备大量的输入和输出,让机器学习或深度学习技术找出其中的上亿个参数。
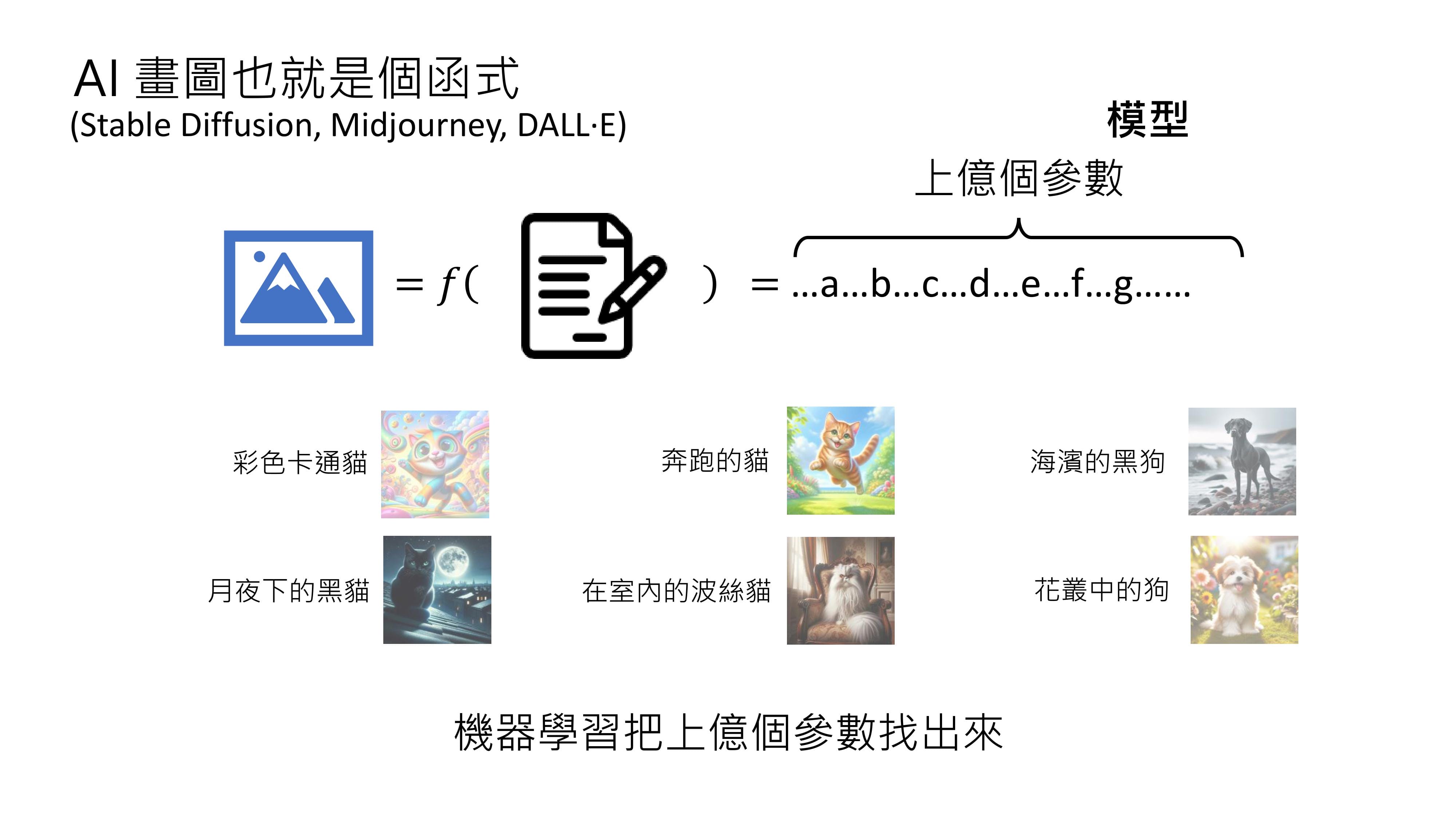
同样的原理也适用于打造能画图的AI,如Stable Diffusion、Midjourney、DALL-E等。这些画图AI也可以看作是函数,输入是一段文字,输出是一张图片,其函数同样复杂,也包含上亿个参数。通过收集大量文字与对应图片的关系,交由深度学习技术找出函数和参数,就能让机器实现输入文字输出图片的功能。
其实,生成这个概念在以往的机器学习课堂中就有提及。在2019年的机器学习课堂上,我就讲过,在机器学习领域,分类这种从有限答案中选择的问题是大家熟悉的领域,而让机器产生有结构的复杂东西,比如生成图片,难度更大。
当时我用拟人化的说法表示,如果机器能成功生成,就相当于它学会了创造。那时,我觉得这一领域还很遥远,就像漫画《猎人》里的库拉皮卡不知道何时才能登陆暗黑大陆一样。但现在到了2024年,虽然库拉皮卡离暗黑大陆依然遥远,但在生成式AI领域,我们已经取得了一定进展,可以说见到了“暗黑大陆的守门人”。
那么,生成式AI面临的挑战是什么呢?按照之前的思路,收集足够多的资料、找出函数就能实现生成式AI。但仔细思考会发现,训练资料可能永远收集不完。
在对生成式AI进行测试时,人类可能会提出各种问题,机器给出的答案可能与训练时完全不同。
比如,让机器写一篇与《缝隙的联想》有关的文章,这个要求可能从未在训练资料中出现过,如果出现就属于泄题了。这是一个全新的问题,而模型要给出正确答案,就需要创造出训练时从未出现过的内容。
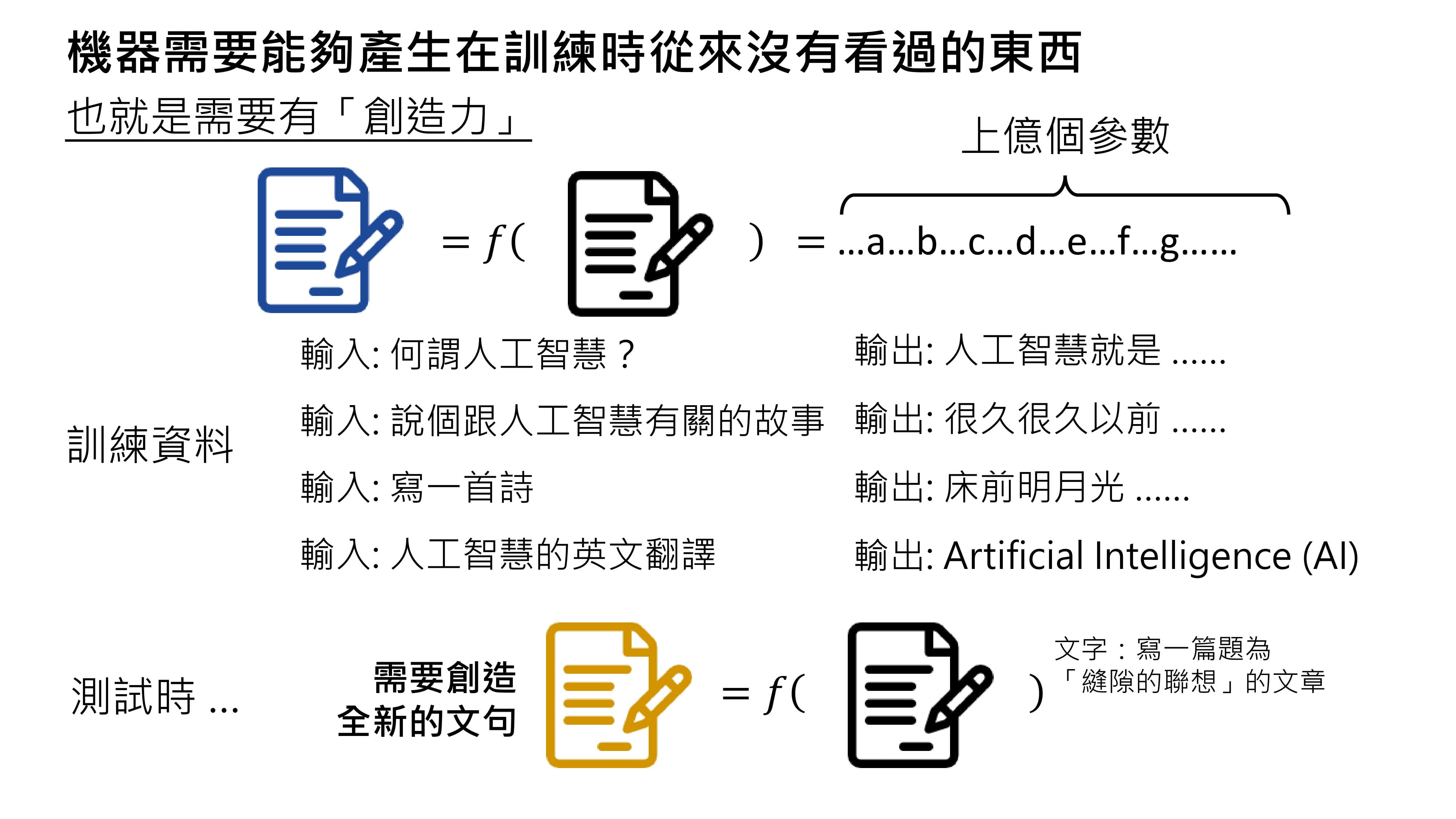
如果机器能在测试时产生训练中从未见过的内容,或许可以说它具有某种程度的“创造力”(这里的“创造力”是一种特定的定义,有人可能并不认同这种定义)。像ChatGPT这样的人工智能是如何做到产生从未见过的答案的呢?
ChatGPT背后的核心原理可以用“文字接龙”四个字概括。
原本生成式AI是一个难题,因为一段文句的可能性无穷无尽。但在ChatGPT中,生成答案被拆解成一系列文字接龙的问题。
比如问“台湾最高的山是哪座”,ChatGPT并不是直接生成完整答案,而是把这个句子当作未完成的句子,预测后面接哪个字合理?
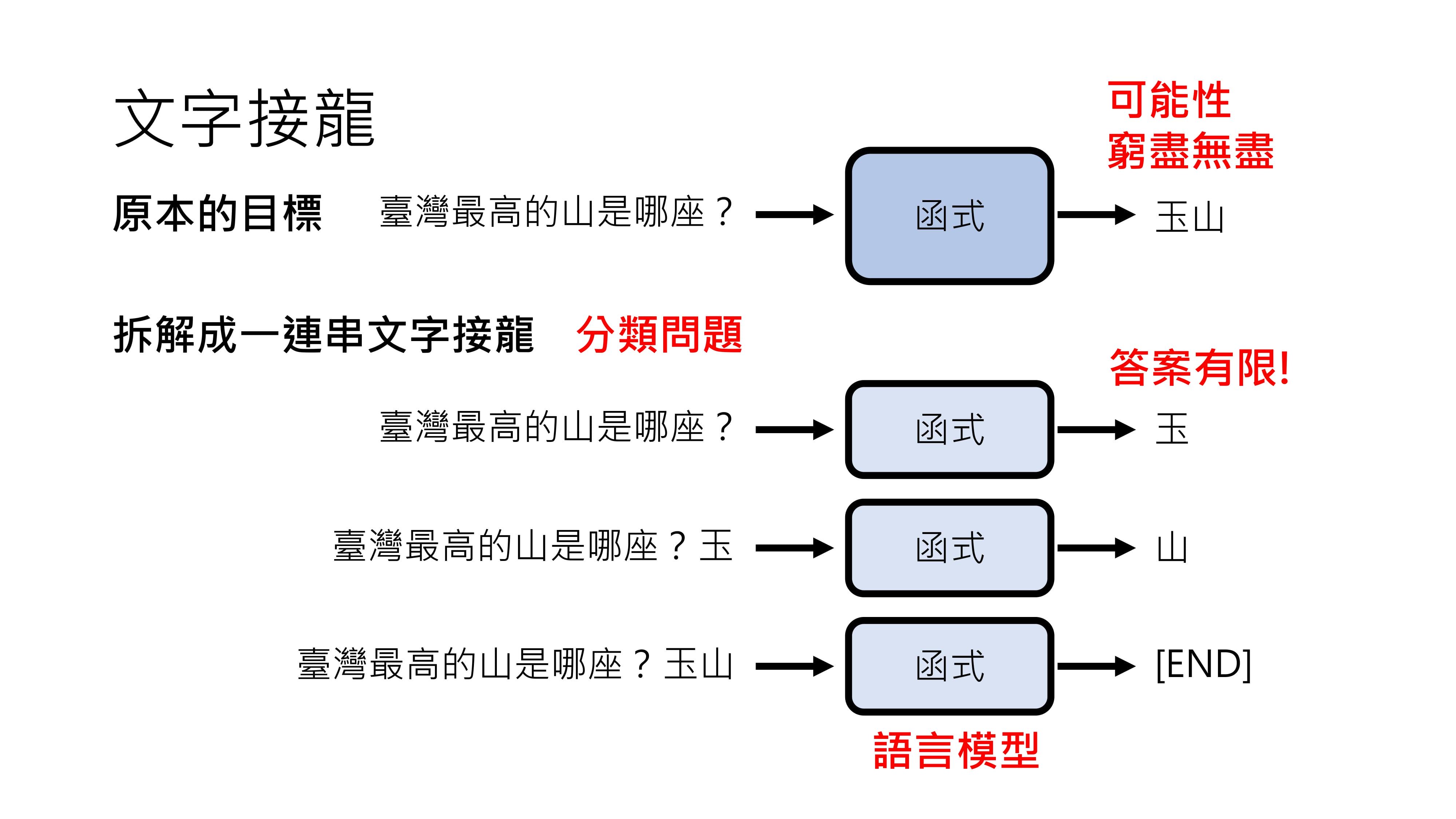
比如接“玉”,然后把“玉”贴到原来句子后面,继续预测“玉”后面接哪个字合理,比如接“山”,当机器认为句子结束时,就输出结束符号,这样就得到了“玉山”这个答案。
能够进行文字接龙的模型叫做语言模型。将生成完整答案的问题转化为文字接龙问题有很大好处,因为文字接龙的答案是有限的。中文常用字大概三四千个,这样一来,原本复杂的生成式AI问题就变成了一系列分类问题,而从有限选项中选择答案是人类擅长的,所以生成文章等难题就变得可解。
不过,语言模型只是生成式人工智能的其中一项技术,生成并不一定要采用文字接龙的方式,还有其他策略。
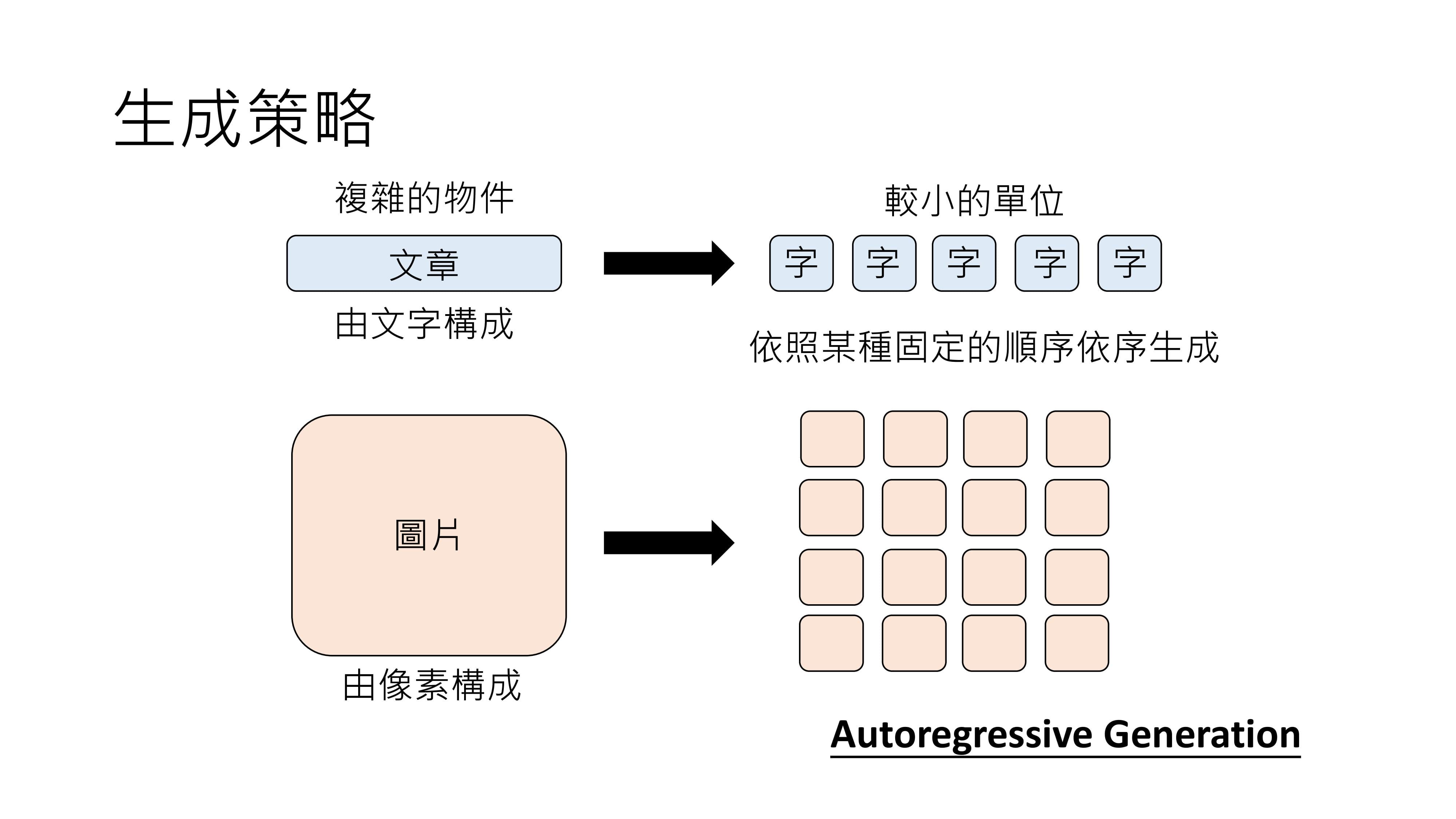
把复杂物件拆解成较小单位,再按照固定顺序生成这些小单位的策略,叫做autoregressive generation,ChatGPT采用的就是这种方式。

同样,生成图片也可以采用类似像素接龙的方式,OpenAI多年前就打造过影像版的GPT,尝试用像素接龙产生图片,但这种方法并没有流行起来,原因在后续讲解生成策略时会说明。

生成式人工智能并非现在才出现,一直有人在研究。2015年我开设的第一堂机器学习课程,当时课程名称叫《机器学习及其深层与结构化》,强调了两个重要技术,一个是深层学习(即现在所说的深度学习,当时Deep Learning还没有统一的中文翻译),另一个是结构化学习,也就是现在的生成式AI。
那时的结构化学习和现在的生成式AI背后的技术已经有很大不同,技术发展非常迅速。虽然生成式AI的概念早就存在,相关应用也早已融入日常生活,比如2006年上线的Google翻译就是生成式AI的一种应用。
翻译时,机器需要生成一段文字,而且输入的文句千变万化,正确的翻译可能在训练资料中从未出现过,所以翻译本身就是一个生成式AI的问题。既然生成式AI早就存在,那为什么现在突然爆火呢?这将在后续课程中为大家剖析。
由于时间有限,接下来我准备回答slido上面的问题。如果大家想听更具技术含量的内容,可以先到我的Youtube频道上搜索相关视频。在Youtube上搜索我的名字,就能找到我的频道,其中第一部时长80分钟、讲解大型模型的影片,可以帮助大家了解GPT是如何被打造出来的。后续课程我们还会讲解更多这方面的知识。
版权声明:本文内容来源于网上同名系列视频《生成式 AI 导论 (2024)》,经大模型翻译和人工校对修正。内容版权归属李宏毅老师所有。如需转载请保留来源链接 (https://llmresources.org)。
参考论文
- 无
术语表
- 人工智能(Artificial Intelligence, AI)
- 生成式人工智能(Generative AI)
- 机器学习(Machine Learning)
- 深度学习(Deep Learning)
- 类神经网络(Neural Network)
- 模型(Model)
- 参数(Parameter)
- 训练(Training,Learning)
- 测试(Testing,Inference)
- 分类(Classification)
- 回归(Regression)
- 语言模型(Language Model)
- 生成策略(Generation Strategy)
- 自回归生成(Autoregressive Generation)
- Transformer(类神经网络的一种)
请访问《术语表》页面。
Comments